- Introduction
- Policies and Support Services
- Research data lifecycle
- 1. Plan & Document
- 2. Collect
- 3a. Analyse
- 3b. Store
- 4. Archive & Publish
- 5. Access & Reuse
- Data Management Plans

The SEA-EU Alliance recognises research data as a valuable asset, pivotal for academic research and its contribution to society. To this effect, the implementation of Research Data Management principles and practices within the SEA-EU partner universities is fundamental to ensure that research data is organised in a harmonised fashion throughout the entire research lifecycle. It also supports the protection, archiving and sharing of data, as and where appropriate.
The purpose of this RDM Toolkit is to serve as a guideline with relevant information on how to effectively manage, preserve and disseminate research data in order to maximise the potential of research. Additionally, it equips researchers with the necessary resources to develop Data Management Plans (DMPs) in line with the FAIR data principles.
Research data refers to the evidence that underpins the answer(s) to research question(s) and hypothesis testing, and validates findings and reproducibility regardless of its form (e.g., print, digital or physical). These might be quantitative measurements and information; or qualitative statements collected by researchers in the course of their work by experimentation, observation, modelling, interviews; or other data-collection methods, or information, derived from existing evidence. Data may be: raw or primary (e.g., direct from creation, measurement or collection); derived from primary data for subsequent analysis or interpretation (e.g., following quality checks, gap filling or as an extract from a larger data set); or derived from existing sources where the rights of reproduction may be held by others.
Some examples of types of research data include measurements, videos, surveys, interviews, photos, samples, transcriptions, recordings, translations, models, algorithms, protocols and standards.
Research Data Management (RDM) is a term that describes the organisation, storage, documentation, preservation, and sharing of data collected and used in a research undertaking. It involves the everyday management of research data throughout the entire research data lifecycle (e.g., using consistent file-naming conventions which describe the type of data within the file, the initials of the Principal Investigator and date, etc). It also addresses collection strategies, backup and storage of data, data documentation, and ethical and legal requirements related to data, data protection, data sharing, data archiving and data destruction.
RDM aims to ensure reliable verification of results, and facilitates emergent and innovative research built on existing information. This Toolkit provides guidance on research data management which acts as a catalyst to adhere to the FAIR Data principles which:
- promotes the integrity of your research
- increases the impact of your research,
- improves the quality of your data,
- supports future use of your research data
The FAIR Data Principles (Findable, Accessible, Interoperable and Reusable) are a set of guiding principles to support the reusability of digital assets.
To make data findable, data and supplementary materials should have sufficiently detailed descriptive metadata, as well as a unique and persistent identifier such as a digital object identifier (DOI). To be accessible, the metadata and data should be understandable to both humans and machines, and data should be stored in a trusted repository. To be interoperable, metadata should use a formal, accessible, shared, and broadly applicable language for knowledge representation, such as agreed-upon controlled vocabularies. To be reusable, data and collections should have a clear usage licence and provide accurate information on provenance.
Main drivers to support Open Science practices and principles are the implementation of policies, tools and support services established by research performing institutions, researchers funders and government entities. Hereunder is a list of resources made available to researchers at institutional and national levels of the SEA-EU partner universities.
- University of Split Repository, Repozitorij Sveučilišta u Splitu serves as a platform to upload research content, including datasets and Data Management Plans (DMPs)
- National Repository, Dabar serves as a platform for all objects, including datasets and Data Management Plans
- Instructions for researchers on how to deposit data in the National Repository, Dabar and for editors of those repositories who will provide support to researchers for publishing data
- Open Science Policy for the University of Split
- High performance computing for Croatian Scientists
- Limesurvey for Croatian Scientists
- Data Management Plan (DMP) Template, Croatian Science Foundation - DMP is mandatory for research projects financed by HRZZ..
- Storage System for data management, PUH. The system is accessed through the AAI@EduHr electronic identity, and the cloud storage available is 200 GB (for a larger amount of space, contact puh@srce.hr).
- Research Data Management Handbook - the aim of this handbook is to support researchers on how to handle, share and reuse.research data.
- Webinar series on Research Data Management
- Research data - what to do with it? - demonstration of storing research data and useful information about the OpenAIRE dashboard
- Research data - what to do with it? - webinar for researchers, postgraduate and doctoral students and librarians
- Research data - what to do with it? - webinar for repository editors and librarians
- Online courses on Platforms, tools, and good practices in the research life cycle targeted for the academic and scientific community and other interested parties (citizens).
- Documentation and anonymization of research data (authentication required)
- drUM is the UM’s data repository. It is powered by an online software platform called Figshare and its main purpose is to collect, archive, organise, and disseminate data produced by UM researchers.
- OAR@UM collects, preserves and disseminates digital research products including articles, working papers, preprints, technical reports, conference papers and data sets in various digital formats generated by UM researchers and academics.
- UM Library”s Open Science Department - Supports researchers with the implementation Open Science principles and practices, as well as, supports with the implementation and maintenance of platforms in support of Open Science.
- Open Access Policy for the University of Malta
- National Open Access Policy
- Guidelines to complete the Data Management Plans for National Science Centre funded projects
- General purpose data repository, RepOD
- Social Data Repository, RDS
- Macromolecular Xtallography Raw Data Repository, MX-RDR
- Courses on Research Data Management for Scientists and Data Stewards, available on the Navoica educational platform:
- Open Science Platform, PON - portal for publications repository, Science Library and Data Repository
- National regulations and reports on Open Science
- The Act of August 11, 2021, on open data and the reuse of public sector information
- Recommendations of the Ministry of Education and Science on the subject of Open Science. (23rd of October 2015) Directions for the Development of Open Access to Publications and Scientific Research Results in Poland
- Report on the Implementation of the Open Access Policy for Scientific Publications in the Years 015-2017
- University of Gdansk Library Toolkit - a dedicated website with information on Research Data Managements for researchers.
- Fahrenheit University Research Equipment Finder - where you can find available research equipment and infrastructure of three Gdansk universities (University of Gdansk, University of Technology and Gdansk Medical University).
- Instructional video on How to write a DMP according to the requirements of the National Science Center?
- Brochure on How to answer the various questions on the DMP form? The guide contains useful hints for DMPs
The Spanish Strategy for Science, Technology and Innovation (EECTI) 2021-2027 is the multiannual reference framework for the promotion of scientific, technical and innovation research in Spain. It promotes open access to research results (publications, data, protocols, code, methodologies, software, etc.) and the use of digital platforms based on open source.
RODIN, Institutional Repository of the University of Cádiz. It provides free access to scientific and academic works generated by the University of Cádiz and allows the deposit of research data.
Guide and template based on the Horizon Europe Data Management Plan Template:
Infographics:
- Kiel University's Guideline on Research Data Management - Adopted in 2015 as 5th RDM-Policy in Germany and contains clear statements on the publication of research data (paragraph 3)
- Kiel University's Data Management Plan Template - Based on the SNSF Data Management Plan template developed by the EPFL Library and the ETH Zurich Library in 2018
- Kiel University's Research Data Repository, opendata@uni-kiel - Open publication of FAIR data with DOI and Scholarly Signposting for researchers of Kiel University
- DFG's (German Research Foundation) Guidelines for Safeguarding Good Research Practice
- All higher education institutions and non-university research institutions in Germany are obliged to implement the guidelines in a legally binding manner in order to receive funding from the DFG
- Includes handling, storage and publication as Open Data according to the standards of the respective discipline, the implementation of the FAIR Principles, and data management planning
- DFG's (German Research Foundation) Statement on the handling of research data - Demands for data management planning following the code of good scientific practice
- DFG's (German Research Foundation) Checklist for planning and description of handling of research data in research projects
- DFG’s (German Research Foundation) Subject-specific recommendations on the handling of Research Data - developed in cooperation with DFG subject committees
- German National Research Data Infrastructure, (Nationale Forschungsdateninfrastruktur, [NFDI]) - The National Research Data Infrastructure aims to systematically make science and research data accessible, networked and usable in a sustainable and qualitative manner for the entire German science system. The data is to be made available according to the FAIR Principles. NFDI consortia, associations of different institutions within a research field, work together in an interdisciplinary manner to implement the goals
- HAL - Open Science national archive for publications
- ResearchData.gouv - A national multi-disciplinary depository for sharing and opening research data
- DMP OPIDoR - Is a platform that guides you through the drafting and implementation of data management plans
- SEA-EU Open Research Data Management Policy Framework:
SEA-EURDMPolicyFramework.pdf
Research Data Lifecycle is a model that illustrates the stages of research data management and describes how data flows through a research undertaking from start to finish. This Toolkit is based on the data lifecycle model that comprises five phases, these being Plan & Document, Collect, Analyse & Store, Archive & Publish, and Access & Reuse.
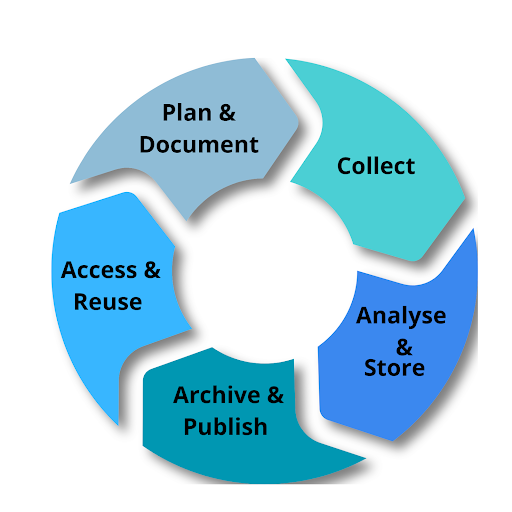
1. Plan & Document
2. Collect
Data Collection Tools Collecting personal and sensitive data Data Anonymisation Using Citizen Science for Collecting Data European Data Protection Regulation (GDPR) Ethics and Scientific Integrity 3a. Analyse
Quantitative Data Analysis Qualitative Data Analysis 3b. Store
4. Archive & Publish
Which data to archive or publish? Publishing your research data Preparing your data for archiving Data Licences 5. Access & Reuse
In the initial stage, you have to identify the data that will be collected or used to answer research questions and/or to test your hypotheses. Planning of the research data management should be done by creating a Data Management Plan (DMP).
A Data Management Plan (DMP) is a plan that outlines how data is managed from the point of collection at the start of a research undertaking, all the way through to its analysis and elaboration of results and how it will be used beyond the original research undertaking. Typically, a DMP will cover areas such as data types, formats and volumes of data collected, metadata, quality control, scientific integrity, specifics concerning access and information concerning publications (as may be applicable). Platforms for the creation of DMPs.
1. Plan & Document
2. Collect
Data Collection Tools Collecting personal and sensitive data Data Anonymisation Using Citizen Science for Collecting Data European Data Protection Regulation (GDPR) Ethics and Scientific Integrity 3a. Analyse
Quantitative Data Analysis Qualitative Data Analysis 3b. Store
4. Archive & Publish
Which data to archive or publish? Publishing your research data Preparing your data for archiving Data Licences 5. Access & Reuse
Data collection is the process of gathering and measuring data from various relevant sources. Guidelines and established methodologies vary across disciplines; so some researchers may use codebooks or protocols, whereas others primarily use traditional methodological steps.
Important aspects of data collection are:- Standardisation: codebooks & protocols
- Structure/organisation of the data
- Data quality assurance methods (more on assessing quality in Access & Reuse)
- Documentation & metadata
- Storage & protection
1. Plan & Document
2. Collect
Data Collection Tools Collecting personal and sensitive data Data Anonymisation Using Citizen Science for Collecting Data European Data Protection Regulation (GDPR) Ethics and Scientific Integrity 3a. Analyse
Quantitative Data Analysis Qualitative Data Analysis 3b. Store
4. Archive & Publish
Which data to archive or publish? Publishing your research data Preparing your data for archiving Data Licences 5. Access & Reuse
Some tools that can help researchers in collecting data include:
LimeSurvey
LimeSurvey is a free and open source online statistical survey web app distributed under the GNU General Public License. As a web server-based software, it enables researchers using a web interface to develop and publish online surveys, collect responses, create statistics, and export the resulting data to other applications.
SurveyMonkey
SurveyMonkey is a private company based in the USA offering a free version of the statistical survey online tool.
Google Forms
A private company based in the USA offering a free easy-to-use online survey tool. It is advised to avoid using Google forms for personal or sensitive data.
Before collecting data, getting approval to perform research with human (or animal) participants at your institution and abide by the other national or discipline regulations is obligatory.
As regulated by GDPR, personal and sensitive data can be collected and processed only if there is a signed consent of the person whose data will be collected and eventually published. This is referred to as informed consent.
The purpose of informed consent is to get permission or approval to participate in the research, and it is valid only if it is freely given, specific, informed and unambiguous. This means that the:
- consent of participation must be given voluntarily and without any coercion or pressure
- participants must be informed about the objectives of your research and how their personal data will be processed via an understandable and easily accessible form and in clear and simple language
- consent must be given for each individual processing activity - if you have more processing activities, participants must be free to choose which purpose they accept, rather than having one generic consent
- statement or a clear affirmative act, preferably in writing, is required. (Participants need to opt in.)
Also, if the research involves processing personal data, the informed consent must be accompanied with a GDPR statement.
More information on informed consent and templates:
- https://www.uu.nl/en/research/research-data-management/guides/legal-considerations/how-to-write-an-informed-consent-form
- https://www.aalto.fi/en/services/how-to-handle-personal-data-in-research
- https://www.rug.nl/digital-competence-centre/privacy-and-data-protection/gdpr-research/informed-consent
- https://www.eur.nl/en/research/research-services/research-quality-integrity/ethical-review/informed-consent
All personal and sensitive data must undergo an anonymisation and/or pseudonymisation procedure to protect the respondent's or participant's identity. Examples of data anonymisation tools include:
- https://ukdataservice.ac.uk/learning-hub/research-data-management/anonymisation/anonymising-quantitative-data/
- Amnesia
Citizen science projects are extremely diverse, but they all share a common goal: to produce scientific knowledge by bringing together research professionals and citizens with the support of partners (most often associations) who help implement the projects. Defining these types of projects is difficult, and it should be noted that each participatory science approach is unique.
The CitieS-Health Toolkit provides a customised and interactive collection of adaptable instruments.
An important aspect of managing data is protecting the privacy of individuals who participate in research projects. The European General Data Protection Regulation (GDPR) regulates personal data processing. Important definitions include:
- Personal data - refers to any information relating to an identified or identifiable natural person (‘data subject’).
- Data processing - refers to any action performed on data, such as collecting, storing, modifying, distributing and deleting data.
- Direct and indirect identification: Some identifiers enable you to single out an individual directly, such as name, address, IP-address, etc. Individuals can also be identified indirectly through:
- a combination of information that may uniquely single out an individual (e.g. a male with breast cancer combined with the town of residency in a breast cancer registry, a pregnant woman over 50, etc.). This includes information in one record and information across different data files or datasets.
- unique information or patterns that are specific to an individual (e.g. genomic data, a very specific occupation, such as the president of a large company, repeated physical measurements or movement patterns that create a unique profile of an individual or measurements that are extreme and could be linked to subjects such as high-level athletes).
- data that is linked to directly identifying information through a random identification code or number such as a tax or health care identification.
- Pseudonymous data - refers to any information that is generally indirectly identifiable is considered to be pseudonymous. This means that it is not anonymous and still qualifies as personal data. Therefore privacy laws, such as the GDPR, apply. This is for example the case when direct identifiers are removed from the research data and put into a key file (or what is usually called a subject identification log). Direct identifiers can then be mapped to the research data through unique codes, so that reidentification is possible.
Ethics and scientific integrity are two very different notions. Ethics is when a study reflects the moral values set out by a community and scientific integrity is good science. Subsequently, a study can be a very good science but with bad ethics or the vice-versa. Based on the fact that ethics is linked to the moral values of a community, it changes depending on a country’s culture. Therefore care must be taken when carrying out multicultural research.
Research data can be categorised as quantitative or qualitative, depending on the methodology and methods used. Quantitative data refers to any information that can be quantified: that is, it can be counted or measured, and given a numerical value. Quantitative data includes numeric values, variables, and attributes. Unlike quantitative data, qualitative data is descriptive: that is, it is expressed in terms of language. Qualitative data includes textual data related to interview transcripts, audio and video recordings, and image materials. So, there are significant differences in analysis and interpretation between quantitative and qualitative research data.
Data analysis refers to the process of manipulating raw data to uncover useful insights and draw conclusions. During this process, a researcher will organise, transform, and model the data collected during the research process.
1. Plan & Document
2. Collect
Data Collection Tools Collecting personal and sensitive data Data Anonymisation Using Citizen Science for Collecting Data European Data Protection Regulation (GDPR) Ethics and Scientific Integrity 3a. Analyse
Quantitative Data Analysis Qualitative Data Analysis 3b. Store
4. Archive & Publish
Which data to archive or publish? Publishing your research data Preparing your data for archiving Data Licences 5. Access & Reuse
One can follow six simple steps to optimise the quantitative data analysis process:
Data cleaning, also referred to as data wrangling, is the process of identifying and correcting or eliminating inaccurate or repeat records from your data. During the data cleaning process, you will transform the raw data into a useful format, hence preparing it for analysis.
Prior to initiating the data analysis process, data must be cleaned so as to ensure that results are based on a reliable source of information.
Useful information on how to process quantitative data files can be found at:
https://www.fsd.tuni.fi/en/services/data-management-guidelines/processing-quantitative-data-files/
Once the cleaning process is completed, a number of research questions will arise which will ultimately uncover the potential of the research data once analysed. Subsequently, it is pertinent to identify the most salient questions one wish to address and answer through one’s analysis.
Breaking down one’s dataset into small defined groups facilitates the data analysis process. Segmenting one’s data will make one’s analysis more manageable, and also keeps it on track.
Data visualisation is an important facet of data analysis whereby graphical representations of the data collected are created. This makes it easier to identify patterns, trends and outliers.
Creating visuals will also enable findings to be better communicated and conclusions are drawn more effectively. Examples of data visualisation tools include Microsoft Excel and Google Charts.
Subsequent to the cleaning, organising, transforming, and visualising your data, the questions outlined at the beginning of the data analysis process need to be revisited. Hence, results are to be interpreted and whether the data has answered one’s original questions needs to be determined.
If the results are inconclusive, try revisiting a previous step in the analysis process. This might be due to the fact that one’s data was too large and should have been segmented further, or perhaps there is a different type of visualisation better suited to one’s data.
While concluding one’s analysis, bear in mind that there might be other solutions to address one’s research questions or support one’s findings. Using a quantitative approach will help one understand what is happening. Subsequently, exploring the possibility of using a mixed method approach by gathering qualitative information will enable a better understanding of why it is happening.
Compared to quantitative data, which captures structured information, qualitative data is unstructured and has more depth. Qualitative data is very often generated through interview and focus groups transcripts, surveys with open-ended questions, observational notes, and audio and video recordings.
There are five steps to follow in order to optimise the qualitative data analysis process:
All data collected, such as transcripts, notes and documents, should be organised in a single place. Also, any sources, demographics and all other information that may help one’s data analysis should be identified. This facilitates accessibility and supports consistent analysis.
Analysing qualitative data is more challenging than analysing quantitative data. Qualitative data can be organised by plotting all data gathered into a spreadsheet; by using specific software such as ATLAS.ti, NVivo and MAXQDA; or by uploading the data in a feedback repository such as Dovetail and EnjoyHQ.
Useful information on processing qualitative data files can be found at: https://www.fsd.tuni.fi/en/services/data-management-guidelines/processing-qualitative-data-files/
Read data to get a sense of what it contains. One may want to keep notes about one’s thoughts, ideas, or any questions that might arise.
Coding is the process of labelling and categorising one’s data into specific themes, and the relationships between these themes. Coding means identifying keywords or phrases and assigning them to a category of meaning. An Excel spreadsheet is still a popular method for coding. However, various other software solutions can help speed up coding. Some examples include NVivo, Dovetail, EnjoyHQ and Ascribe. Advances in machine learning have now made it possible to read, code and structure qualitative data automatically. This type of automated software is offered by Thematic Analysis Software.
This is where one starts to answer one’s research questions. Analysis is the process of uncovering insights through the codes that emerge from the data and identifying meaning correlations. It is also pertinent to note that each insight is distinct, with ample data to support it.
In circumstances where codes are too broad to extract meaningful insights, primary codes should be divided into sub-code. This process, which will improve the depth of one’s analysis, is referred to as meta-coding.
To conclude one’s analysis process, the research findings need to be reported and communicated. This can be done by preparing a series of charts, tables and visuals which can be generated using data visualisation software such as Power BI, Tableau, and Looker Studio.
Proper data storage is crucial for ensuring that it is stored securely, accessible when needed and shared in a way that maximises its value. To store one’s data properly, consider the following actions:
Identify a suitable data storage location. Recommended storage media include cloud services, the university network drive or designated data repositories. Cloud services enable one to collaborate with other partners beyond the university. It is important to ensure that the service provider is trustworthy and that regular backups are made. The university network drives are suitable for collaborating with other researchers within the university community. Analysed data can be stored and shared via thematic or institutional repositories.
Managing the different versions and copies of one’s research data carefully is extremely important. Suggestions include the protection of raw data, distinguishing between temporary and master copies of one’s data, backing-up one’s master copy in a physically distinct location, and setting up a strategy for identifying your latest version control.
Raw data is protected by being stored in a separate folder that is set to ‘read only’. Actual analyses should be performed on a working copy of one’s data. Since one’s working files may be constantly changing and to keep track of the latest version, it is essential to select one place where the master copies of one’s data are located. To rule out the possibility of losing one’s master copy, it is recommended that back-ups of one’s master data files are stored in different locations. To identify a particular version of a file or folder, the use of an extension to the file name with ordinal numbers indicating major and minor changes (eg 'v1.00', 'v1.01', 'v2.06') is recommended. In a version control table (or file history or log file), one can document what is new or different in each major version that one keeps.
Presuming that during the course of one’s research numerous files are generated, all with different content, coming up with a logical and standardised folder structure and file naming convention before starting a research project is imperative.
For the folder structure, anticipate the type of files to be produced and envision the folders for these files. The structure should be scalable to enable expansion. A well-arranged folder structure in which folders and sub-folders are hierarchical and follow each other logically is invaluable in quickly navigating one’s data and finding what one requires. It can be very helpful to draw up one’s folder structure in a diagram in one’s DMP.
For file naming, clear coded names built from elements such as project name, project number, name of research team/department, measurement type, subject, date of creation and version number is recommended. Only use characters from the sets A-Z, a-z, 0-9, hyphen, underscore, and dot. Don't use special characters such as &%$#), as different operating systems can assign different meanings to these characters. An example of a file name could be: ‘MicroArray_NTC023_20230416.xls (content description, project number, date: international standard). File name conventions could also be included in the DMP.
To facilitate retrievability and accessibility, it is essential to generate the appropriate metadata. The scope of the metadata is to provide useful information about one’s data. Bear in mind that metadata should be structured, machine readable and interoperable.
As not all the existent file formats are widely accessible or future-proof, it is recommended to use a standard format for one’s stored files. The format is indicated by the file extension at the end, such as .wmv, .mp3, or .pdf. The following characteristics will help to ensure access:
- non-proprietary
- open documentation
- supported by many software platforms
- wide adoption/common usage
- no (or lossless) compression
- no embedded files or scripts
Different measures to secure one’s files include the protection of data files, computer system security and physical data security. Information in data files can be protected by controlling access to restricted materials with encryption. Avoid sending personal or confidential data via email or through File Transfer Protocol (FTP). Subsequently, transfer it as encrypted data e.g. via SURFfilesender and WeTransfer. Also, if needed, data should be destroyed in a consistent and reliable manner. Note that deleting files from hard disks only removes the reference to it, not the file itself. Overwrite the files to scramble their contents or else use secure erasing software. The computer one uses to consult, process and store your data, can be secured by using a firewall to protect one’s data from viruses, installing anti-virus software, installing updates and upgrades for one’s operating system and software, and using secured wireless networks. Furthermore, use passwords on all one’s devices and do not share them with anyone. If necessary, also secure individual files with a password. With simple measures, one can also ensure the physical security of one’s research data. These include locking one’s computer/laptop, locking the door when out of one’s office, not leaving unsecured copies of one’s data lying around, and keeping non-digital material which should not be seen by others in a locked cabinet or drawer.
Other useful tools to support research data during this phase include:
- PsFCIV — PowerShell File Checksum Integrity Verifier - open source tool for checking the integrity of shared digital files
- Programs for encryption of files, folders, removable media and hard drives:
- Axcrypt (licenced)
- BitLocker (for Windows)
- FileVault2 (for Mac)
- Eraser (permanent deletion of files)
1. Plan & Document
2. Collect
Data Collection Tools Collecting personal and sensitive data Data Anonymisation Using Citizen Science for Collecting Data European Data Protection Regulation (GDPR) Ethics and Scientific Integrity 3a. Analyse
Quantitative Data Analysis Qualitative Data Analysis 3b. Store
4. Archive & Publish
Which data to archive or publish? Publishing your research data Preparing your data for archiving Data Licences 5. Access & Reuse
There is a difference between archiving and publishing data, and it is mainly dependent on the research cycle, since publication of data is the final step of the research data lifecycle. Archiving data means ensuring that a copy of one’s dataset is kept (usually by one’s host institution) in a secure location for the long term (10 years or more). Publishing data is making one’s data publicly available, whether that is a restricted public or an open public. Also, decisions on what others may do with one’s data needs to be set out through the use of a licence.
1. Plan & Document
2. Collect
Data Collection Tools Collecting personal and sensitive data Data Anonymisation Using Citizen Science for Collecting Data European Data Protection Regulation (GDPR) Ethics and Scientific Integrity 3a. Analyse
Quantitative Data Analysis Qualitative Data Analysis 3b. Store
4. Archive & Publish
Which data to archive or publish? Publishing your research data Preparing your data for archiving Data Licences 5. Access & Reuse
The amount of data accumulated during the research is often considerable and not all of it should be archived and/or published. Archiving all digital data leads to high storage, maintenance and managing costs. Any data archived or published should apply the FAIR Data Principles.
Normally, research data is published either by being deposited in data repositories or data journals.
Besides institutional, repositories are divided in two main categories: general-purpose or discipline-specific. The role of a repository is to archive and/or publish data. A repository should ensure that data is accessible for the years to come with technological advances.
Re3data is a global registry of research data repositories for different academic disciplines. It includes repositories that enable permanent storage of and access to data sets to researchers, funding bodies, publishers, and scholarly institutions. Re3data promotes a culture of sharing, increased access and better visibility of research data.
CoreTrustSeal is a certification that indicates that the repository has complied with the coretrust requirements and has obtained a high level of trustworthiness.
Choosing a Data Repository
When publishing one’s data, consider choosing an institutional data repository, multi-disciplinary repository or a discipline specific repository. Multi-disciplinary repositories can also offer good visibility for one’s data. An example of a multi-disciplinary repository is Zenodo which is often used as a repository for EC funded research. Some other general purpose repositories include FigShare, Mendeley Data, DataDryad, and OpenScienceFramework. Discipline-specific repositories are used when the repository supports the type of data to be shared according to subject areas.
When choosing a repository for permanent research data storage, The repository must comply with the FAIR Data Principles. The compliance with FAIR principles of the repository can be checked on the FAIRsharing portal.
Questions that should be answered when choosing an appropriate repository include:
- does it support the formats of the data being stored - does it provide the necessary amount of storage space - are backup copies made? The answers to these questions should be found in the repository policies.
- is the repository reliable and sustainable (hardware, software, support)? Does it have a certificate, for example, CoreTrustSeal, to prove its reliability?
- does the repository enable tracking of data usage statistics (number of metadata views, data downloads)?
A list of thematic data repositories can be downloaded here:
ThematicDataRepositories.pdf ![]()
Research data can also be published as supplementary material or information to a research paper with a scientific journal. Some scientific publishers have detailed policies for the publication of research data in addition to research papers.
There is also a possibility of publishing research data as an independent element of research in publications that specifically publish only research data, the so-called data journals. Due to their specificity, such journals are not oriented towards data analysis and theoretical contributions, so the paper in a data journal usually consists of a summary, introduction, description of data, methods and materials, conclusion and the possibility of data reuse.
A list of thematic data journals can be downloaded here:
ThematicDataJournals.pdf ![]()
VU Amsterdam recommends that a dataset should consist of the following documents:
- Raw or cleaned data (if the cleaned data has been archived, the provenance documentation is also required)
- Project documentation
- Codebook or protocol
- Logbook or lab journal (when available, dependent on the discipline)
- Software (& version) needed to open the files when no preferred formats for the data can be provided
A data licence is a legal arrangement between the creator of the data and the end-user, specifying what users are permitted to do with their data. The type of licence one chooses will define the terms of use. It is advisable to use the least restrictive licence possible.
The funding body
- If the entity financing the project is a public body in Europe, then the data should be made public and freely available with a CC-O licence (as long as there are no legal restrictions e.g. the data is confidential or contains personal data).
- If the entity financing the project is a private company, then a contract should be established to ascertain who owns the data and whether the data is to be published and the associated licence.
The type of data
- A more restrictive licence can be added to prevent companies using data to make financial revenue or for a cause that is not in line with the European values.
- Data processing may be required prior to sharing the data, such as publishing part of a data set or anonymising your data.
CC Licences
Creative Commons Licences (CC licences) provide a standardised way to grant public permission to use creative works and data under copyright law. From the re-user perspective, a Creative Commons licence on a copyrighted work provides details of how the data can be re-used.
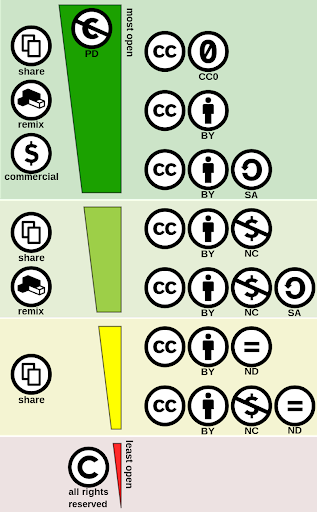
Licences other than Creactive Commons
The Open Data Commons Open Database License (ODbL) is a copyleft licence agreement intended to allow users to freely share, modify, and use a database while maintaining this same freedom for others.
Copyleft
Copyleft licence is the legal technique of granting certain freedoms over copies of copyrighted works with the requirement that the same rights be preserved in derivative works. In this sense, freedom refers to the use of the work for any purpose, and the ability to modify, copy, share, and redistribute the work.
The Registry of Research Data Repositories (Re3data) can be used in two ways; either to find open science data sets that can be reused or to find the best repository for publishing data. Re3data is a global registry of research data repositories that covers research data repositories from different academic disciplines. It includes repositories that enable permanent storage of and access to data sets to researchers, funding bodies, publishers, and scholarly institutions. Re3data promotes a culture of sharing, increased access and better visibility of research data.
Although the essential requirement for reusing a data set is that it complies with the FAIR Data Principles, that alignment does not guarantee data quality. According to the Research Data Management: Information Platform for Max Planck Institute Researchers, data quality is a context-dependent and multidimensional concept, which refers to reusing other scientist data and keeping the quality potential of the data they produce. Data quality applies to datasets and their documentation (metadata) and presentation at the level of individual data (e.g. tables), which is essential for reuse. In particular, it is important to check for the quality of data origin, that is, discover how individual values/data points for a given variable (or field) recorded, captured, labelled, gathered, computed, or represent and be cautious of any missing data.
Further information on data quality:
- https://src.isr.umich.edu/what-is-data-quality-and-how-to-enhance-it-in-research/
- https://ukdataservice.ac.uk/learning-hub/research-data-management/format-your-data/quality/
- https://www.imperial.ac.uk/research-and-innovation/research-office/preparing-and-costing-a-proposal/worktribe/data-quality/
Citing research data is mandatory, just as citing any other material used in research, such as journal articles, books or conference proceedings. Basic elements of data citation, based on recommendations by Taylor & Francis Author Services, Digital Curation Centre Guide on How to Cite Datasets and Link to Publications, and Columbia University Instructions on Citing data Sources are:
- Author(s)
- Date of publication (the date the dataset was made available, the date all quality assurance procedures were completed, and/or the date the embargo period expired [if applicable])
- Title of dataset, Material Designator: the tag “[dataset]” or “[database]”
- Publisher or repository
- Persistent locator/identifier (e.g., DOI)
- Version (when appropriate)
- Date accessed (when appropriate)
The way in which these elements are combined and sequenced depends on the chosen or designated citation style (e.g.. APA, MLA, Harvard, etc.). Examples of various citation styles can be found here.
1. Plan & Document
2. Collect
Data Collection Tools Collecting personal and sensitive data Data Anonymisation Using Citizen Science for Collecting Data European Data Protection Regulation (GDPR) Ethics and Scientific Integrity 3a. Analyse
Quantitative Data Analysis Qualitative Data Analysis 3b. Store
4. Archive & Publish
Which data to archive or publish? Publishing your research data Preparing your data for archiving Data Licences 5. Access & Reuse
The Data Management Plan (DMP) is a plan that outlines how data is managed from the point of collection at the start of a research undertaking, all the way through to its analysis and elaboration of results and how it will be used beyond the original research undertaking. The scope of a DMP is to ensure that data is well-managed, organised, and preserved for future use.
- Saves time and effort in the long run - It is pertinent to prepare a DMP at the initial stages by organising and annotating details pertaining to one’s data since it serves to identify and mitigate data management issues.
- Increases research efficiency - Well-managed data is easier to understand and use, both for the researcher who generated and collected the data, and for other researchers who may wish to reuse it.
- Facilitates data sharing and preservation - A DMP can help researchers to choose the right platform for their data and to format it in a way that is compatible. Preserving data makes it more accessible to other researchers and can lead to new and unexpected discoveries.
There are a number of open source DMP creation tools/templates available. These tools also allow researchers to work collaboratively on a DMP. The SEA-EU Alliance encourages the use of an open source DMP creation tool. Such tools support researchers with the creation of DMPs, provide templates which can be used, cater for sharing and codesigning of DMPS, facilitate the publication of DMPs and support with the archiving of the DMP.
Some examples of commonly used, open source DMP tools include:
- DMPtool - A user-friendly web-based tool first established in the US. The tool prides itself on being a living tool, meaning that it is continuously being updated.
- DMPonline - Similar to DMPtool, DMPonline is feature-rich, continuously updated, web-based tool that allows researchers to create a DMP and collaborate with others. It is based on the open source DMPRoadmap codebase, which is jointly developed by the Digital Curation Centre (DCC) and the University of California Curation Center (UC3).
- DMP Assistant - A web-based tool that walks researchers step-by-step through a number of key questions about data management.
- ARGOS - Based on OpenDMP and developed by OpenAIRE, ARGOS is another web-based tool that simplifies the management, validation, monitoring and maintenance of DMPs.